

مهندس نرم افزار - مهندس اتکاپذیری
زیرساخت کافهبازار: فرهنگ دوآپس را چگونه شکل دادیم؟
دوآپس چیست و چرا؟
چیزی که باعث شده ما توی کافه بازار اهمیت زیادی برای اتکاپذیری (reliability) سرویسهامون داشته باشیم اینه که ما داریم به ۴۵ میلیون کاربر فعال سرویس میدیم و هر لحظه از دسترس خارج بودن بازار ضرر مالی زیادی بهمون وارد میکنه . سه تا فاکتور هست که برای ما اهمیت داره: کارایی (performance)، دسترسپذیری (availability)، مقیاسپذیری (scalability). کارایی یعنی برنامه بتونه توی زمان معقول با استفاده از منابع معقول جواب کاربر رو بده. زیاد شدن زمان پاسخ دهی میتونه باعث نارضایتی و از دست رفتن کاربرها بشه. دسترسپذیری یعنی سعی کنیم ارتباط کاربرها با سرور همیشه برقرار باشه چون اگه ارتباط کاربر با سرور قطع بشه عملا از اپلیکیشن بازار استفادهای نمیتونه بکنه و مقیاسپذیری هم یعنی اگه با رشد ناگهانی کاربرها مواجه شدیم، بتونیم همچنان جوابگوی درخواستها باشیم.
ولی یک نکته مهم اینجا هست. تلاش ما برای افزایش اتکاپذیری نباید باعث کند شدن فرایندهای توسعه محصول ما بشه!
به صورت سنتی تیم توسعه (Development) و تیم عملیات (Operations) جدا از همن. هدف تیم توسعه اضافه کردن قابلیتهای جدید به برنامست و هدف تیم عملیات حفظ کردن شرایط پایداری سرویس. مشکلی که این فرآیند ایجاد میکنه تضاد منافع بین تیمهاست. تیم توسعه دوست داره فیچرهای جدید رو هر چه سریعتر توسعه بده در حالی که تغییر توی سرویس یعنی به خطر افتادن پایداری! پس تیم عملیات همیشه باید مطمئن باشه تغییرات جدید مشکلی توی سرویس ایجاد نمیکنن. اگه اختیار عمل رو کامل به تیم توسعه بدیم احتملا پایداری سرویس ازبین میره و اگه اختیار عمل رو به تیم عملیات بدیم توسعه محصول به کندی پیش میره.
اینجاست که ما به یک تعامل خوب و سازنده بین این دو تا تیم نیاز داریم. این هدفِ تیم عملیاته که پایداری سرویس رو تضمین کنه. ولی خیلی مواقع پیش میاد که بهبود پایداری نیاز به تسلط روی سورس کد داره برای همین تیم توسعه باید توی این فرآیند کمک بکنه. همینطور توسعه سریعتر و اتکاپذیری بیشتر، دو کفه یک ترازو هستند پس برای رسیدن به بهترین تعادل به ارتباط قوی بین تیم توسعه و عملیات و همینطور مارکتینگ و محصول نیاز داریم.
طبق تعریف، دوآپس ترکیبی از ارزشها و فرآیندها و ابزارهاست که باعث نزدیک شدن فرآیند توسعه و فرآیند عملیات به هم میشه تا به سازمان این قابلیت رو بده که بتونه سرویسهاش رو با سرعت و کیفیت به دست کاربر برسونه.
کافه بازار چطوری به این ساختار رسید؟
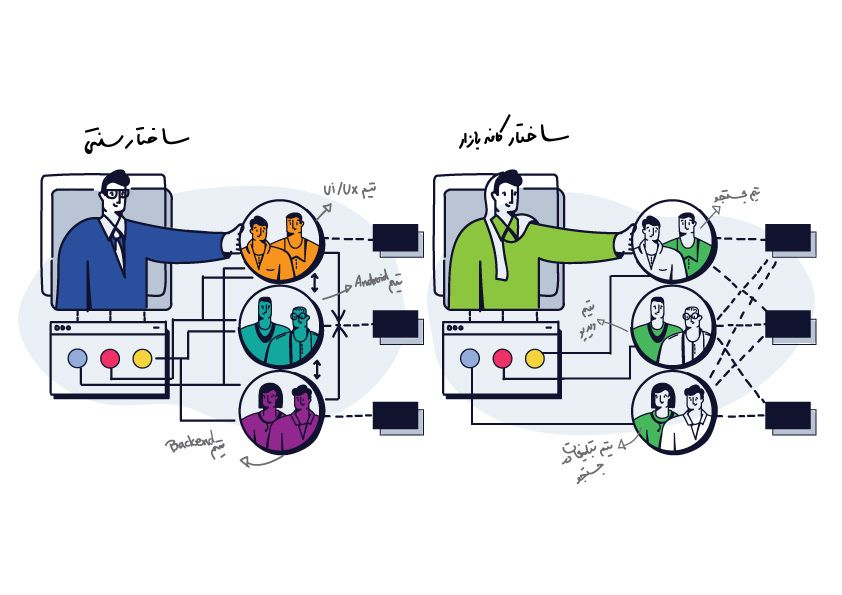
اون اول وقتی تیم فنی کافه بازار کوچک بود، مرزی بین توسعه و عملیات دیده نمیشد. همون کسی که کدی رو مینوشت، اول تستش میکرد و بعد روی سرورها دیپلوی میکرد تا سرویس به روز بشه. خودش هم کارای مانیتورینگ و بقیه کارای عملیاتی رو انجام میداد. با بزرگ شدن تیم فنی چاره ای نبود که تقسیم وظایف صورت بگیره. ما بین یک دوراهی قرار گرفتیم. راه اول این بود که نقشهای مختلف رو از هم جدا کنیم و هر کدوم توی یک تیم مستقل باشن که به component team معروفه. یعنی یک تیم بکاند داشته باشیم و یک تیم زیرساخت (و همینطور تیم اندروید و فرانت و مارکتینگ و غیره) یا اینکه بیایم تیمها رو بر اساس هدف نهاییشون، یعنی رسوندن یک سرویس خاص به دست کاربر جدا کنیم و توی هر تیم افراد مختلف با نقشهای مختلف وجود داشته باشن که به feature team معروفه.
ما با الهام گرفتن از اسپاتیفای سمت راه دوم رفتیم. توی ساختاری که ما بهش رسیدیم همچنان مثل قدیم که یک شرکت کوچک بودیم مرزی بین توسعه و عملیات دیده نمیشه و رفع کردن مشکلات مقیاسپذیری و دسترسپذیری، مقابله با مخاطرات احتمالی که به بخش عملیات معروفه توسط توسعهدهندههای بکاند انجام میشه.
توی فرهنگ کافه بازار فقط زمانی میشه از تیمی توقع مسئولیتی رو داشت که اون تیم قدرت و اختیار تمام و کمال روی اون موضوع داشته باشه. ما نمیتونیم از تیمی توقع داشته باشیم که دسترسپذیری و کارایی یک سرویس رو بهتر کنه در حالیکه تیم دیگهای کدش رو توسعه داده.
این نوع شکستن تیمها نیاز ما رو به معماری میکروسرویس زیاد کرد. اگه قرار بود یک تیم بتونه با استقلال به سمت اهدافش بره منطقا اولین چیزی که باید از بقیه مستقل میکرد سورس کد پروژهای بود که روش کار میکنه. مهاجرت به سمت معماری میکروسرویس یک شبه انجام نشد و چند سال طول کشید تا خورد خورد هر تیم پروژه خودش رو از سرویس یکپارچه کافه بازار جدا کنه.
در حال حاضر، هر تیم کافه بازار چندین میکروسرویس داره و دیگه برای نوشتن یک فیچر جدید، به کد نوشتن روی سورس کدی که توسط تیمهای دیگه مدریریت میشه تقریبا نیازی نیست.
مدیریت کردن این همه میکروسرویس خودش کار سختیه. برای همین ما توی کافه بازار نقشی به اسم «صاحب سرویس» تعریف کردیم. «صاحب سرویس» کسیه که بیشترین تسلط رو روی اون میکروسرویس داره و مسئولیت اینو داره که کدش رو همیشه با کیفیت نگهداره، کدای بقیه رو بررسی کنه و اگه مشکلی براش رخ داد در اسرع وقت درستش کنه.
خوبی و بدی این ساختار چیه؟
خوبی:
- این مدل شکستن باعث میشه تضاد منافع بین dev و ops باعث کند شدن ما در رسیدن به یک تجربه خوب برای کاربرامون نشه.
- شناسایی اینکه مشکل یک میکروسرویس از سورس کدشه یا از پلتفورمی که روش مستقر شده (شامل تنظیمات سرور، دیتابیس، کش (cache) و غیره) راحت تر پیدا میشه. توی مدل سنتی شرایطی پیش میاد که تیم ops برای بهبود اتکاپذیری یک سرویس کلی وقت میذارن درحالیکه ممکنه اون مشکل با یک تغییر کوچیک توی کد حل شه.
- فرآیندهای release و deployment راحتتر میشن چون دیگه خبری از یک سورس کد خیلی بزرگ نیست که هر کس فقط بخشی ازش رو بلد باشه به جاش کلی میکروسرویس کوچیک داریم که صاحبش روی کدش کامل تسلط داره و میتونه سریع یک کد جدید رو بررسی کنه و روی محصول اصلی deployش کنه.
- بین وقت گذاشتن روی توسعه فیچر جدید یا وقت گذاشتن روی بهتر کردن reliablity خیلی تعادل برقرار میشه. چرا که ارتباط درون تیمی بین افراد یک تیم خیلی راحت تر از ارتباط بین تیمی صورت میگیره.
بدی:
- تجربههایی که داخل تیمها به دست میاد تو همون تیم میمونه و به سختی با بقیه به اشتراک گذاشته میشه. مثلا فرض کنید یکی از بچهها برای افزایش کارآیی میکروسرویسی که صاحبشه وقت زیادی روی tuning دیتابیس میذاره. اگه یک میکروسرویس از یک تیم دیگه مشکل مشابه داشته باشه، به احتمال زیاد صاحب میکروسرویس دوم باید از اول وقت بذاره. ولی توی ساختار سنتی چون افراد با توجه به مهارتشون توی یه تیم قرار میگیرن انتقال دانش بینشون راحت اتفاق میوفته. جلسات هفتگی chapter برای بهتر کردن این مشکل برگزار میشن ولی یه جلسه توی هفته هیچوقت نمیتونه جای چندین ساعت همتیمی بودن رو بگیره.
- وقت زیادی صرف کارای تکراری میشه. برای مثال یک تیم زمانی رو اختصاص میده که برای مانیتورینگ سرویس ها از prometheus استفاده کنه و برای میکروسرویس های داخل تیم، کلی alert و dashboard مختلف میسازه. اگه یک تیم دیگه هم بخواد از prometheus استفاده کنه باید همون کارارو تکرار بکنه در حالی که شاید یک سری alert و dashboard تکراری وجود داشتن که میشد فقط یک بار به صورت کلی انجامش داد.
- داشتن یک نیرو که کل تمرکزش فقط روی مباحث زیرساختی باشه (DevOps Engineer) توی هر تیم هزینه زیادی داره و برای ما ممکن نیست. صاحبهای سرویسها هم بیشتر از نصف وقتشون رو دارن روی توسعه اون سرویس میذارن برای همین دانششون توی مباحث زیرساخت سطحی تر از یک نیروی متخصصه.
ماموریت تیم پلتفورم چیه؟
بالاتر به معایب ساختاری که ما بهش رسیدیم پرداختیم. تیم پلتفورم بازار با هدف ارائه سرویس و ابزار برای میزبانی از میکروسرویسهای بازار و بهبود اتکاپذیری آنها تشکیل شد تا بتونه معیابی که بهش اشاره کردیم رو کمرنگتر کنه. ولی توی تشکیل تیم پلتفورم یک چالش بزرگ داشتیم. چالش اصلی این بود که نمیخواستیم ساختار قبلی رو بهم بزنیم چون در اون صورت مزیتهاش رو از دست میدادیم. تیم فنی شرکت به تعدادی تیم محصولی شکسته شده بود که اهداف خودشون رو داشتن ما و ما نمیخواستیم با تشکیل تیم پلتفورم استقلال اون هارو از بین ببریم. توی ساختار سنتی تیم پلتفورم میتونه نظارت سختگیرانه روی تیم توسعه داشته باشه و برای افزایش پایداری خودش مستقیما وارد عمل بشه. ولی توی ساختار کافه بازار که استقلال تیم ها برای ما مهمه. تیم پلتفورم نمیتونه بقیه تیمهارو مجبور به رعایت کردن یک سری الگو بکنه یا خودش مستقیم وارد بشه و اون الگو هارو پیاده سازی کنه.
برای حفظ استقلال تیمهای محصولی ما به خود تیم پلتفورم به چشم یه تیم محصولی نگاه کردیم با این تفاوت که مشتریهای تیم پلتفورم دیگه کاربرهای کافهبازار نیسن و در واقع تیمهای محصولی دیگه شرکت رو به عنوان مشتری خودمون میبینیم و باید براشون خلق ارزش کنیم. تلاش میکنیم تا مشکلاتشون رو شناسایی کنیم و ابزارهایی ارائه بدیم که اون مشکل رو حل کنه. اگه ابزاری ارائه بدیم و تیمی ازش استفاده نکنه، یعنی توی شناسایی مشکلات تیمهای محصولی خوب عمل نکردیم. برای هل دادن تیم های محصولی برای رعایت کردن الگوهای درست سعی میکنیم ابزارهایی ارائه بدیم که انجام دادن یک کار از روش درستش راحت تر از انجامش به صورت اشتباه باشه.
کار هایی که تا الان توی تیم پلتفورم انجام دادیم:
بالاتر خیلی کلی از اهداف و آرمان های تیم پلتفورم گفتیم توی این بخش اشاره میکنیم که واقعا چه کارهایی رو تا الان تونستیم انجام بدیم. بعضی از این کارها خودش یک بلاگ پست جدا نیاز داره که حتما سعی میکنیم در آینده بنویسیم ولی توی این پست جهت آشنایی با تیم پلتفورم صرفا در حد چند خط بهشون اشاره میکنیم.
- ایجاد chaos یا هرج و مرج در کوبرنتیز
بیشتر سرویسهای ما توی کافه بازار روی کوبرنتیز مستقر شدن. باید بدونیم که اپلیکیشنهایی که روی کوبرنتیز مستقر میشن باید در برابر restart شدن و منتقل شدن به یک node دیگه مقاوم باشن. اگه اینطور نباشه اضافه و کم کردن یک سرور به کلاستر کوبرنتیز میتونه باعث داون تایم بشه و همینطور کوبرنتیز وقتی تشخیص بده یک سرویس حالش خوب نیست ریاستارتش میکنه. اگه قرار باشه اون سرویس با ریاستارت شدن حالش بدتر بشه پس عملا استفاده از کوبرنتیز منفعتی برای ما نداشته. دیده میشد که خیلی از تیم ها این مسئله رو رعایت نمیکنن و خب ما هم نمیتونستیم مستقیم وارد تیمها بشیم و چک کنیم که تکتک میکروسرویسهایی که تیمها نوشتن نسبت به این اتفاقات مقاوم هستن یا نه. راه حلی که ما تصمیم گرفتیم انجامش بدیم ایجاد اختلال عمدی روزانه بود که با این اختلالها تیمها بتونن سریع مشکلاتشون رو شناسایی و رفع کنن. شبیهسازی خاموش شدن یک node کوبرنتیز و کاهش کیفیت شبکه داخلی کوبر دو تا از هرجومرجهایی هستن که ما روزانه ایجاد میکنیم.
- ارائهدادن زیرساخت مانیتورینگ
با بررسی مستندات downtime های ۲ سال گذشته (که به postmortem معروفن) به این نتیجه رسیدیم کم کیفیت بودن مانیتورینگ سرویسهامون اصلیترین دلیل کاهش uptime بوده برای همین تیم ما داره تلاش میکنه که کیفیت مانیتورینگ رو در کافه بازار بیشتر کنه.
برای بهتر کردن کیفیت مانیتورینگ تا الان دو تا رویکرد رو جلو بردیم. اولی ارائه ابزارهای زیرساختی برای مانیتورینگ بوده مثل ارائه sentry و prometheus و grafana. و دومین رویکردمون درست کردن داشبوردها و آلرتهای عمومی و کلی برای همه میکروسرویسها. به این صورت که الان تیمهای محصولی کافه بازار میتونن مشخصات میکروسرویس جدیدشون جای مشخص ثبت کنن تا به صورت خودکار براشون سیستم alerting و monitoring ساخته شه.
- سامانه نظارت
همونطور که اشاره کردیم یکی از مشکلات ما متمرکز نبودن صاحب سرویسها روی کارهای زیرساختی بود که باعث میشد خیلی از مواقع به دلیل کم بودن اطلاعات یا حواس پرتی کار تظیمات اشتباهی روی سرور قرار بگیره. برای کم کردن این مشکل ما پروژه «ناظر» رو شروع کردیم. در حال حاضر پروژه ناظر قابلیت نظارت روی کوبرنتیز و ماشینهای مجازی رو داره و احتمالا در آینده نظارت روی سورس کد سرویسها هم بهش اضافه بشه. توی قدم اول ما اول اومدیم اشتباهات متداولی که بچهها موقع deploy کردن یک سرویس روی کوبرنتیز یا setup کردن یک سرور مجازی انجام میدن رو شناسایی کردیم. بعد اومدیم پروژه ای نوشتیم که به صورت زمانبندی شده بیاد کل کلاستر کوبرنتیز و سرورهامون رو نظارت کنه و اگه یکی از این اشتباهات دیده شد به تیم مربوطه پیام بفرسته. خاموش بودن firewall سرور یا رزرو اشتباه منابع توی کوبر، دو تا از ۸ نوع مشکلی هستن که پروژه ناظر قابل به شناسایی اونها در لحظه است. همینطور ناظر یک صفحه گزارش داره که به صورت هفتگی توی جلسه توسط نماینده تیم و CTO بررسی میشه تا تیم ها از تعداد اشتباهاتی که توی تنظیمات زیرساختیشون دارن آگاه باشن.
- راه اندازی محیط staging
سورس کد بزرگ کافه بازار و میکروسرویسهای زیاد توسعه محصول را سخت کرده. توسعه و تست یک کامپوننت شاید چالشی نداشته باشه ولی تست نهایی اون کامپوننت در کنار همه میکروسرویسهای بازار نیاز به یک محیط بزرگی داره که به staging معروفه. هر تغییر قبل از رسیدن به دست کاربرهای نهایی میتونه توی محیط staging که یک نسخه کامل از کل بکاندهای بازاره تست بشه. یکی از کارهای تیم پلتفورم که سمتش رفتیم سادهتر کردن این فرآیند بود. مثلا تلاش داریم با استفاده از سرویس مش ریکوئستهای alpha tester ها رو از ریکوئستهای production جدا کنیم و اگه میکروسرویسی خودش رو staging معرفی کرد ریکوئست پروداکشن دریافت نکنه. ابزار دیگه ای که برای اینکار توسعه دادیم پروژه staging database ه. این پروژه هر روز از دیتابیس اصلی یک بکآپ میگیره و برنامهنویسها میتونن با استفاده از cli یک نسخه از دیتابیس دیروز رو روی سرور اجرا کنن و بهش وصل بشن.
جمع بندی
توی این پست توضیح دادیم که چطور فرهنگ دوآپس رو توی کافه بازار پیاده کردیم. اینکه ما نیروی متمرکز برای کارهای Ops نداریم و کارهای عملیاتی توسط خود برنامهنویسها انجام میشه. همینطور به چالشهای این ساختار یعنی سطحی بودن دانش و وجود کارهای تکراری اشاره کردیم و با مثال سعی کردیم توضیح بدیم چطور تیم پلتفورم بازار سعی داره بدون دخالت مستقیم روی پروژه های بچهها این چالشها رو برطرف کنه تا کیفیت و اتکاپذیری سرویسهای بازار افزایش پیدا کنه.
مطلبی دیگر از این انتشارات
از هزاران درخواست در روز به هزاران درخواست در ثانیه
مطلبی دیگر از این انتشارات
ژوپیتر چیست؟
مطلبی دیگر از این انتشارات
استفاده از هوش مصنوعی و مدلهای زبانی بزرگ (LLMها) در بازار